{kind=link}
{kind=link}
Multi-Modal Fusion Transformer for Visual Question Answering in Remote Sensing
This repository contains the code of the paper Multi-Modal Fusion Transformer for Visual Question Answering in Remote Sensing presented at SPIE Image and Signal Processing for Remote Sensing. This work has been done at the Remote Sensing Image Analysis group by Tim Siebert, Kai Norman Clasen, Mahdyar Ravanbakhsh, and Begüm Demir.
T. Siebert, K. N. Clasen, M. Ravanbakhsh, B. Demir, "Multi-Modal Fusion Transformer for Visual Question Answering in Remote Sensing", SPIE Image and Signal Processing for Remote Sensing, Berlin, 2022.
If you use the code from this repository in your research, please cite our paper:
@article{VBFusion2022,
title={Multi-Modal Fusion Transformer for Visual Question Answering in Remote Sensing},
author={T. {Siebert} and K. N. {Clasen} and M. {Ravanbakhsh} and B. {Demіr}},
booktitle={SPIE Image and Signal Processing for Remote Sensing},
year={2022}
} Abstract
With the new generation of satellite technologies, the archives of remote sensing (RS) images are growing very fast. To make the intrinsic information of each RS image easily accessible, visual question answering (VQA) has been introduced in RS. VQA allows a user to formulate a free-form question concerning the content of RS images to extract generic information. It has been shown that the fusion of the input modalities (i.e., image and text) is crucial for the performance of VQA systems. Most of the current fusion approaches use modality-specific representations in their fusion modules instead of joint representation learning. However, to discover the underlying relation between both the image and question modality, the model is required to learn the joint representation instead of simply combining (e.g., concatenating, adding, or multiplying) the modality-specific representations. We propose a multi-modal transformer-based architecture to overcome this issue. Our proposed architecture consists of three main modules: i) the feature extraction module for extracting the modality-specific features; ii) the fusion module, which leverages a user-defined number of multi-modal transformer layers of the VisualBERT model (VB); and iii) the classification module to obtain the answer. In contrast to recently proposed transformer-based models in RS VQA, the presented architecture (called VBFusion) is not limited to specific questions, e.g., questions concerning pre-defined objects. Experimental results obtained on the RSVQAxBEN and RSVQA-LR datasets (which are made up of RGB bands of Sentinel-2 images) demonstrate the effectiveness of VBFusion for VQA tasks in RS. To analyze the importance of using other spectral bands for the description of the complex content of RS images in the framework of VQA, we extend the RSVQAxBEN dataset to include all the spectral bands of Sentinel-2 images with 10m and 20m spatial resolution. Experimental results show the importance of utilizing these bands to characterize the land-use land-cover classes present in the images in the framework of VQA.
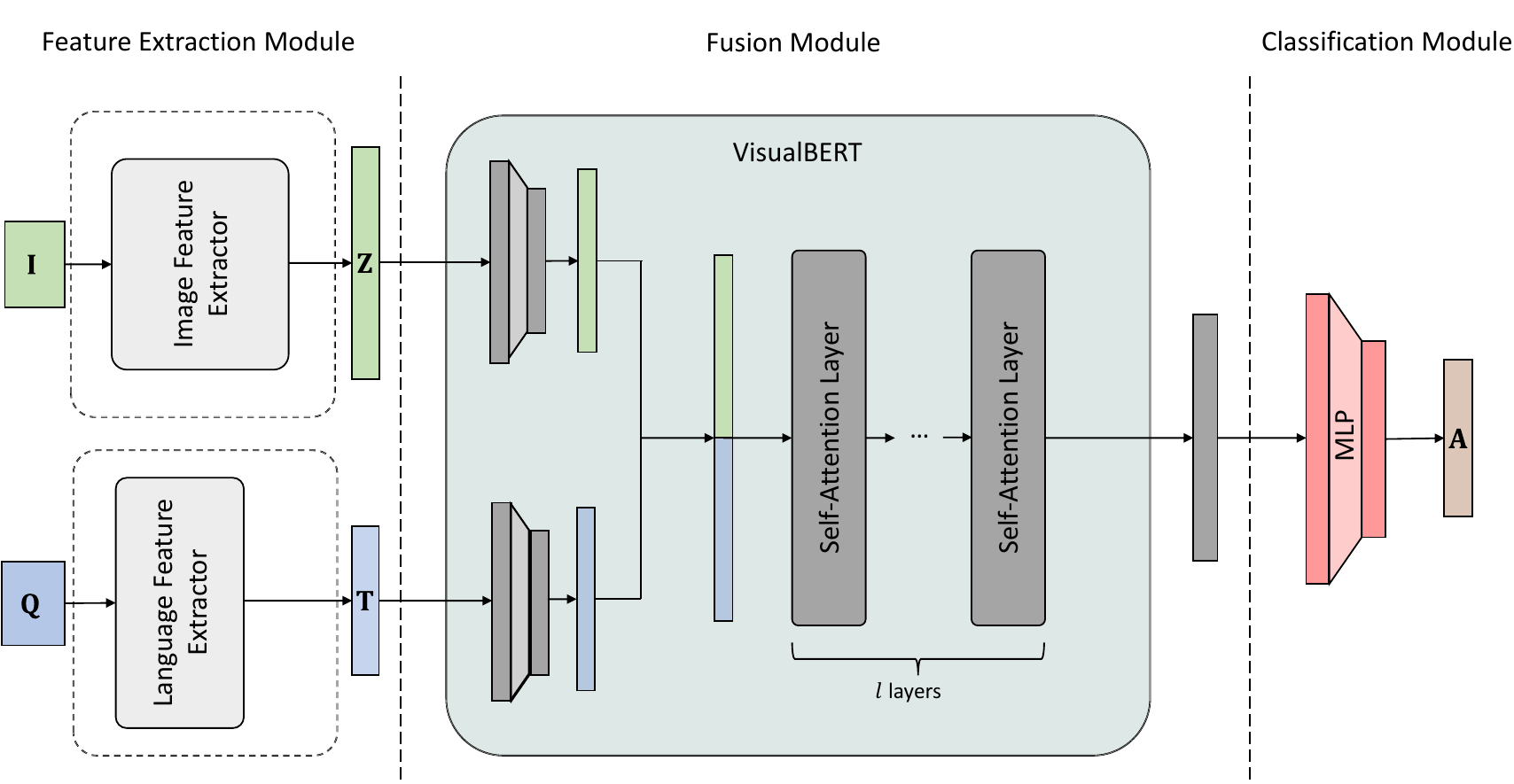
with the image feature extractor as follow:
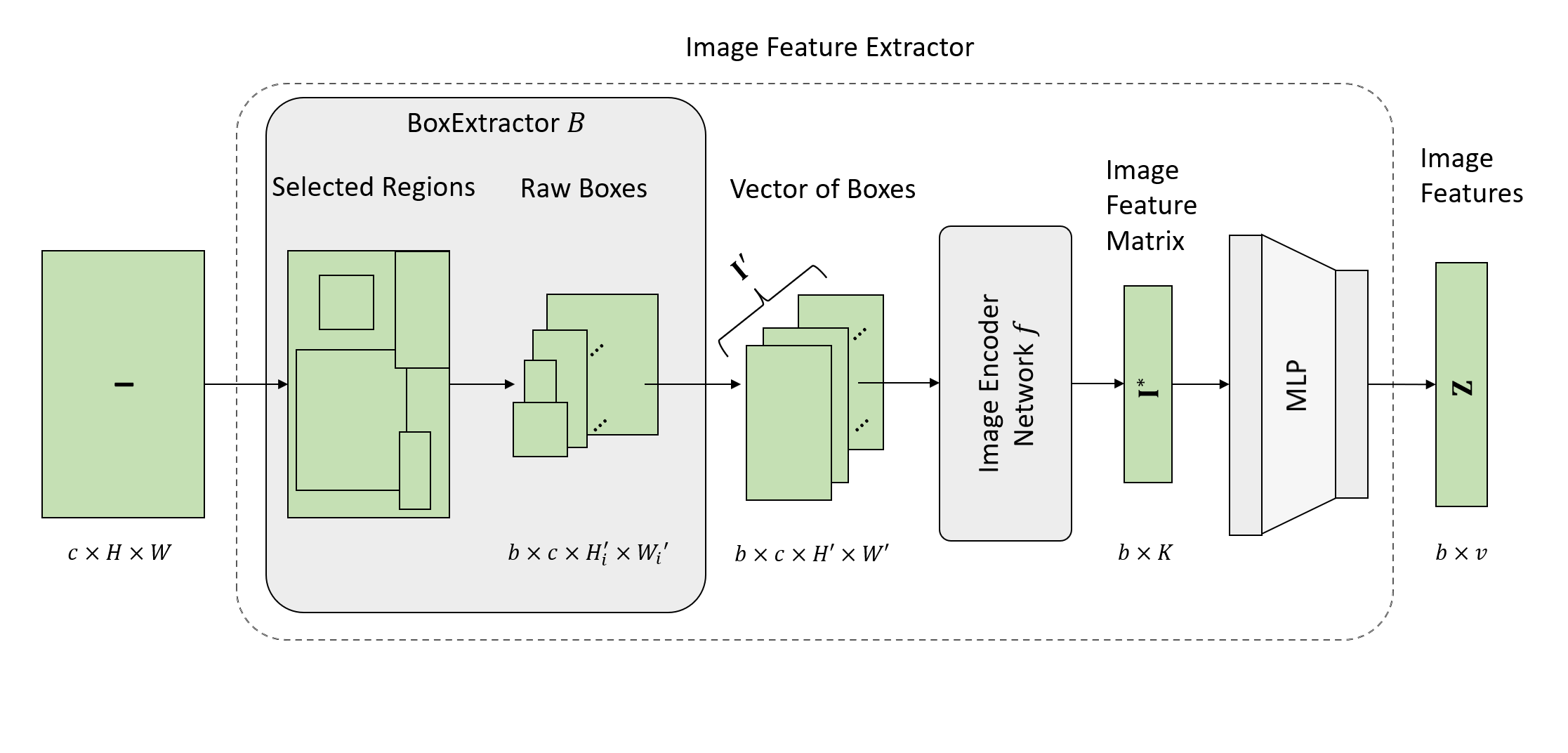
Requirements
The code was developed on Python 3.7.1 with the following dependencies:
torch 1.11.0+cu112
torchmetrics 0.9.1
torchvision 0.12.0+cu112
numpy 1.23.0
opencv-python 4.5.5
scikit-learn 1.1.1
scikit-image 0.19.3
pytorch-lightning 1.6.5
transformers 4.20.1
tqdm 4.64.0
typer 0.4.1
wandb 0.12.21Usage
Train and test on RSVQAxBEN Dataset
- At first, you should download the RSVQAxBEN dataset
- Unzip its content
- The first step is to create the features
RGB:
Run the
prepo_3_bands.pyscript with the following parameters
-
imgFolder: Path to the unzipped images -
dstFolder: Path where the image features will be stored -
model_name: name of the image encoder network (currently only resnet is supported) -
transform: transformations which should be applied to the images
If the extraction process is done, you can use the train_RGB.py file with the following configurations to train the model:
For loading the image-question-answer pairs, you need to provide all needed paths in the data_files dict. These are the paths to the training, validation and test jsons of the image, question and answers. You may find them in the downloaded data.
10 band:
Download the BigEarthNet to get the additional bands: BEN
Run the prepo_10_bands.py script with the following parameters
-
imgFolder: Path to the unzipped BEN images -
dstFolder: Path where the image features will be stored -
model_checkpoint: Path to 10 band pretrained ResNet152 -
name_mapping_file: Path to the mapping json between the BEN file names and index of the RSVQAxBEN (use name_mapping.py to create the file) -
model_name: name of the image encoder network (currently only resnet is supported) -
transform: transformations which should be applied to the images
- If the extraction process is done, you can use the
train_RGB.pyortrain_10_bands.pyfile with the following configurations to train the model:
For loading the image-question-answer pairs, you need to provide all needed paths in the data_files dict. These are the paths to the training, validation and test jsons of the image, question and answers. You may find them in the downloaded data.
Hyper-parameter configuration
-
num_gpus: number of gpus you can use -
num_workers: number of workers you can use for the Dataloader
For the VisualBERT architecture:
-
visual_embedding_dim: defines the embedding dimension of the visual features, should be allways 2048 -
num_hidden_layers: number of VisualBERT layers -
number_outputs: number of answers used for training
For the Dataloader
-
ratio_images_to_use: this parameter is used to select a subset of the dataset, number between 0 and 1 -
sequence_length: length of the output of the BertTokenizer
For the training
-
num_epochs: number of training epochs -
batch_size: batch size -
lr: learning rate
Provide the relevant paths for the VQALoader i.e. the paths of the image features (RGB or 10B) and the paths of the .json's.
Then run this skript without further arguments. Optionally, you can use typer to run the script with the selected arguments from the command line.
- To test the model use the
test_model_10b.ipynbortest_model_RGB.ipynbfile. Provide again the data_files, hyperparameters and the image features paths for the VQALoader. Also the checkpoint of the model to test is needed. You can store the results inwandbor they are printed.
Train and test on RSVQA-LR Dataset
- First you should download the RSVQA-LR dataset.
- Load the RSVQA file and unzip its content (the Images folder inside is also zipped). You need then a folder for the image matrix features. For creating the features, use the ImageFeatureExtractor class in the code/RSVQA-LR/image_feature_extractor.py file .
The arguments are:
-
imgFolder: Path to you the images (unzipped) -
dstFolder: Path to folder where the image features should be stored
optional:
-
model_name: name of the image encoder network (currently only resnet is supported) -
transform: transformations which should be applied to the images
Then you can run the image feature extraction.
- train the model by using the code/RSVQA-LR/image_feature_extractor.py file. For loading the image-question-answer pairs, you need to provide all needed paths in the data_files dict. These are the paths to the training, validation and test jsons of the image, question and answers. You find them in the downloaded data.
Hyper-parameter configuration
For the VisualBERT architecture:
-
visual_embedding_dim: defines the embedding dimension of the visual features, should be always 2048 -
num_hidden_layers: number of VisualBERT layers -
number_outputs: number of answers used for training
For the Dataloader
-
ratio_images_to_use: this parameter is used to select a subset of the dataset, number between 0 and 1 -
sequence_length: length of the output of the BertTokenizer
For the training
-
num_epochs: number of training epochs -
batch_size: batch size -
lr: learning rate
Provide the path to the image matrix features for the VQALoader and if the boolean train, if you are in training or not. You also have to provide a path for the ModelCallback class. Here your checkpoints will be stored.
Then run the file.
- To test the model use the test.ipynb file.
- select your model architecture in the first cell.
- provide the paths
- addtionally, in the testing cell you have to provide the model checkpoint path
- your results will be printed in the last cell
Acknowledgement
We thank EOLab for giving us access to their GPUs. This work is funded by the European Research Council (ERC) through the ERC-2017-STG BigEarth Project under Grant 759764 and by the German Ministry for Economic Affairs and Climate Action through the AI-Cube Project under Grant 50EE2012B.
The code in this repository to facilitate the use of the Multi-Modal Fusion Transformer for Visual Question Answering in Remote Sensing is available under the terms of MIT license:
Copyright (c) 2022 the Authors of The Paper, "Multi-Modal Fusion Transformer for Visual Question Answering in Remote Sensing"
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.